
はじめまして、2020年10月アクセンチュアからestieに転職して働いているぴーまんといいます!
生後6ヶ月になる飼い猫のけんたろうがジャレて噛み付いてくるため、全身傷だらけの日々です。

estieではデータエンジニアとして2つのサービス「estie.jp」と「estie pro」にデータを届けるためのデータパイプラインの整備をしています。また、e-賃料という機械学習を用いた賃貸オフィスの成約賃料予測モデルの開発を行っています。
e-賃料についての記事は↓
inside.estie.co.jp
今後より詳細なe-賃料の記事も掲載を予定しているので、乞うご期待です。
各ドメインデータの特徴に合わせてパイプラインの構成を考える必要があるというのは、データエンジニアにとって共通かつ永遠の課題です。今回は、事業ドメインである不動産業界ならではのデータパイプライン自動化に際して生じる悩みを、卵料理(コード名)で解決した話をしていきます。
The origin of 卵料理
estieのデータチームが扱うツールやリポジトリには、卵料理の名前をつけるという慣習があります。この慣習が生まれた理由は下記の通り。
- 「xxxx_normalizer」や「yyyy_checker」等、機能の説明となる名前をつけると、名前以上の役割が発生したときに混乱の元になる
- 「estie.jpとestie proは1つのタマゴから生まれた黄身と白身のようなサービス」というメンバーの言葉が元になっている
弊社VPoE青木がホワイトボードに描いた、データ処理を示す歯車マークがふにゃふにゃで目玉焼きに見えたから

estieデータチームの課題
estieでは、データが「データベースに溜め込まれる -> 綺麗になる -> サービスに届けられる」までのフローが自動化され、日々ユーザーに価値を届けています。文字面だけを見ると当たり前のことをやっているように見えますが、データを扱う仕事には様々な課題がついて回ります。
どんな業界でも業界特有の慣習や、それに伴ってできる「データの癖」のようなものがあり、もちろん不動産業界も例外ではありません。
データの癖 その1:ビル名、住所表記の揺れ
例えば、同じビルの情報を複数のデータソースから得られた場合に、それぞれのデータソースで名前や住所の表記が異なることは日常茶飯事です。
この問題に対して弊社サウナ部長兼データエンジニアのいっしーが面白いアプローチを試しています。
qiita.com
データの癖 その2:「平米」ではなく、「坪」
表記ゆれよりも不動産特有のデータの癖が顕著なものとして「単位」があります。世間一般で面積というと「平米」「㎡」等の、SI単位系が使われることがほとんどだと思いますが、不動産業界では「坪」がスタンダードです。estieのプロダクトも「坪」表記に統一されています。
しかし「不動産業界でスタンダード」というわりに、世の中に溢れるデータは完全に統一されておらず、データを溜め込み綺麗にする過程で、「平米」を検知して「坪」に変換してあげる必要もあります。今や私も「坪」に慣れましたが、estieのデータを触り始めた当初は「平米」と「坪」の変換に怯える毎日でした。
(ちなみに「平米」->「坪」は0.3025をかけると変換できます。覚えておくと物件探しの際に役立つかもしれません。)
データの癖 その3:データの入力形式
また、estieではビルの賃料情報を過去から蓄積し、estie proの1つのサービスとして提供しています。元データによっては人が打ち込んだものもあるので、サービスに適した構造に整形してあげる必要があり、この処理ロジックを作るだけでも地味に手間がかかります。
さらに入力者によって形式がバラバラで、パイプラインのロジックでは全形式に対応しきれない可能性があります。
以上3つの例は氷山の一角ですが、この一見泥臭いとも見えるこの作業が不動産業界最大級であるestieのデータベースを作り上げ、他社では保持することができない網羅感と正確さを持ってオフィスの物件情報や募集情報を提供することができています。

上記のような、綺麗にするべきデータについて、自動で適用される加工ロジックで一部検知されず、どうしてもデータの重複が残ったままになったり、正しくない情報が移送されてしまうことが起こり得ます。そもそも取得元のデータが間違っている場合も厄介で、これらの問題は自動パイプラインに任せるには限界があり、人の目で確認し、手動でのデータ修正がどうしても必要な場面が出てきます。
さらに、estieでは独自に収集したデータを直接データベースに保存するような場面もあり、例えばオフィスビルには「館銘板(かんめいばん)」という、何階にどんな企業が入居しているかが書いてあるボードがあったりするのですが、その館銘板を写真に収め、その情報を人の手でデータ入力するという作業も必要になってきます。
このように、データチームでは自動パイプライン をより良いものにしていく傍らで、
- 自動パイプラインで対応できないデータの手動修正
- 独自収集データの手入力
というマニュアル作業も行っており、これによりestieのデータをさらに充実させることができています。
estieではこれらの対応作業は「スポット対応」と呼ばれており、他のパイプラインissueと同列に整理され、手の空いている人が順次対応するという運用をとっていました。スポット対応の作業はエンジニアにとって必ずしも楽しい作業とは言えず、優先度が下がってしまい、対応が後手後手に回ってしまうということも少なくありませんでした。ここで、いかにスポット対応の運用をシンプルにわかりやすいものにして、データチームの負担を減らすかが大きな課題として見えてきました。
omuriceの導入(課題解決 Step1)
データチームでは、スポット対応をよりシンプルな運用にするために、まず「omurice」という「手動で上書き」を実現するための仕組みを導入しました。構成としては下図のようになっています。この構成によって、手動で上書きしたデータが自動でパイプラインを流れてくるデータで更新されないようになっています。
(ちなみに由来は「overwrite manually」の頭文字「OM」から。さらにデータをご飯に見立て、そこに手動で追加するデータを卵に見立てて「オムライス」と、この記事を書いている最中にデータチームにこじ付けてもらいました。)

データベースの構成ですが、以前は収集したデータを溜め込む「estie_master」と呼ばれるDBとサービス側のDBとに分けて、基本的には各サービスに必要な情報をestie_masterからそれぞれ移送する仕組みをとっていました。omuriceの導入に当たって、estie_masterとサービスDBとの間にもう1層「data_catalog」と呼ばれるDBを追加しました。そしてestie_masterの中に「omurice」というテーブルを用意して、修正対象のテーブルとカラム、そして上書きする値の情報を保持できるようにし、適宜修正したい情報を書き込むと、その修正情報がdata_catalogに反映される仕組みになっています。
つまりサービスに反映されるまでの流れとしては
1. データがestie_masterに溜め込まれる
2. omuriceに修正したい情報を書き込む
3. estie_masterへomuriceに書き込まれた情報が上書きされ、data_catalogに移送される
4. data_catalogから各サービスへ必要な情報が移送される
となります。
ここで残った課題としては、
- テーブルに書き込むためにはSQLのクエリ文を書いてコードを実行する必要があり、結局スポット対応ができる人はほとんどデータチームに限られ、負担は大きく変わらない
- あくまでもデータの「上書き」のための仕組みであり、新規情報(新規竣工ビルや新規募集等)の追加ができない
等があり、さらなる仕組みの改善が求められます。
medamayakiの導入(課題解決 Step2)
omuriceの導入後、依然として残っている課題を解決するために、「medamayaki」と呼ばれるツールが導入されました。

データベースの構成はomurice導入の段階から大幅に変わっており、概念としては、自動パイプラインでwarehouseに溜め込まれたデータをmedamayakiで管理・修正更新するという設計になっています。
medamayakiはRuby on Railsで実装されており、Administrate(リポジトリ)というgemを主体として作られています。このgemは本来、Ruby on Railsで作られたアプリのDBを管理者権限で編集したりするためのものですが、この直感的にDBのテーブルを編集できるという機能、必要であればデフォルトの表形式ではなく自由なビューを作ってデータを挿入できる点が、データチームが抱えている課題にクリーンヒットしました。
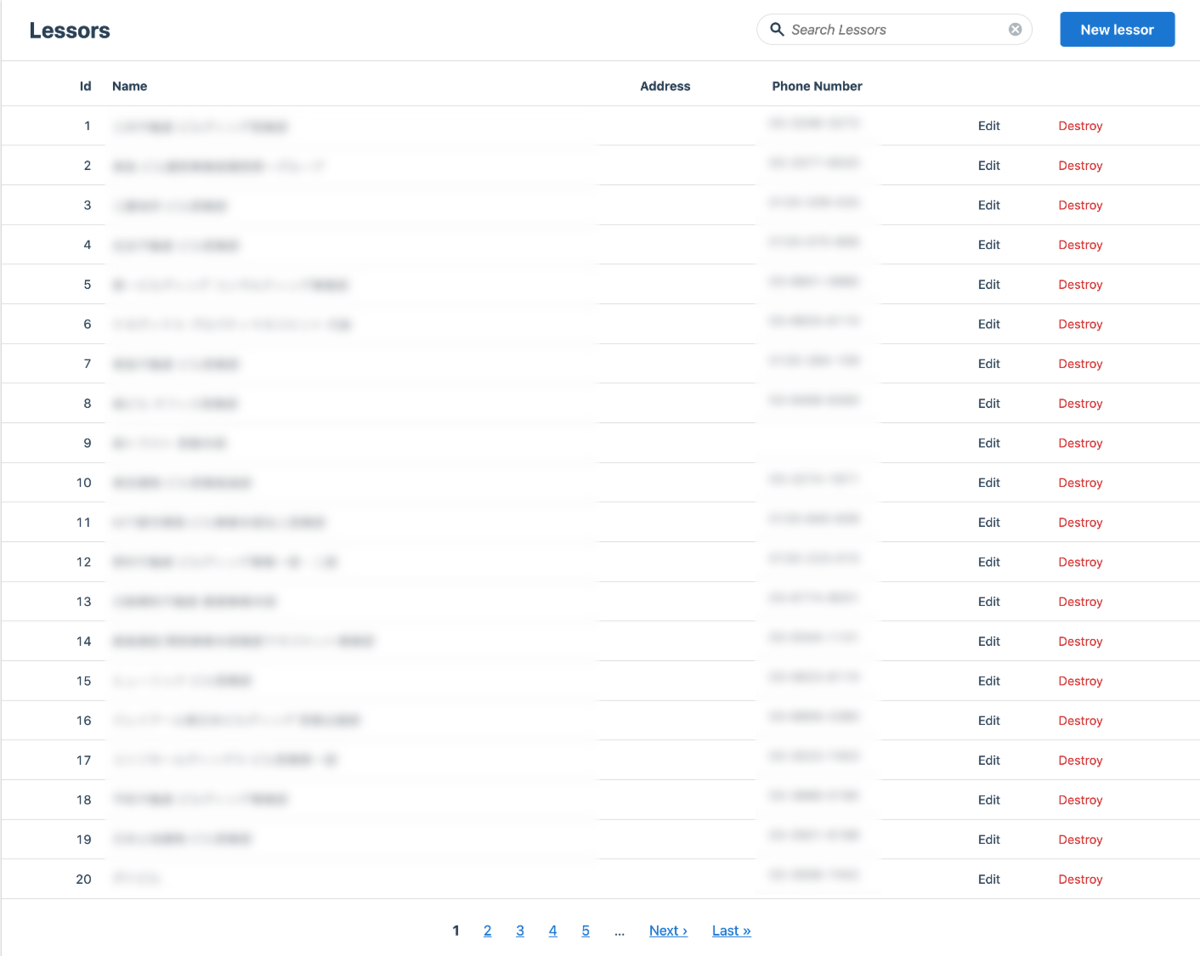
上画像のように、medamayakiユーザーはSQLクエリなど全く触らず、GUI上で直感的にデータの修正・追加をすることができます。このツールによって、上で挙げられた
- スポット対応ができる人が限られている問題
- データ「追加」ができない問題
が解決されます。また、ユーザ認証や修正承認機能などを設けることで安全にデータ更新を行ったり、貢献度を可視化してランキングで称賛しあおうという計画がスタートしています。
まだ社内で全体実用には至っていませんが、今後エンジニアであろうとなかろうと、社内の誰もがデータの不備に気づいたタイミングで迅速な承認プロセスと共に修正が行えるようにするべく、運用の体制構築を進めています。
また、このmedamayakiの運用をはじめとした、データのクオリティを高めるための試みの1つで、データチームのサブチームとして「Data Quality」チームが発足されました!Data Qualityチームの詳細については、いっしーが今後記事を書いてくれると思うので、そちらも乞うご期待です!!
最後に
現在estieでは日本中にある不動産データを収集し、最強の不動産データプラットフォームを共に作るデータエンジニアを募集しています!
少しでも興味を持たれた方がいらっしゃれば、気軽にお話しできればと思います。TwitterのDMよりお声がけください!
twitter.com
採用情報はこちらをご確認ください!
hrmos.co